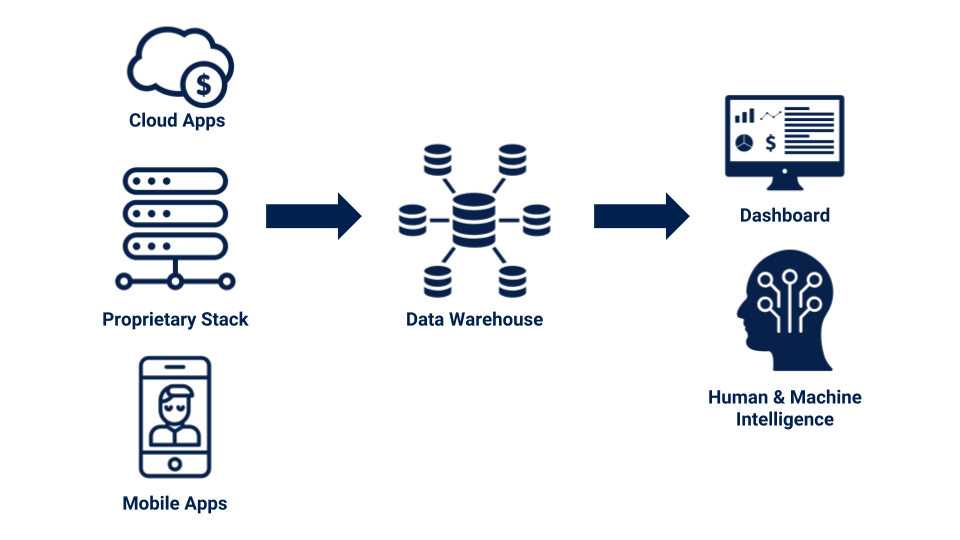
Solve the “data last-mile problem” to unlock the full analytics capabilities for your business.
Adding P to ELT
If you worked with a data-engineer, you may have heard the word ETL or ELT.
- E for Extracting data from the source.
- T for Transforming from raw data to clean and useful information.
- L for Loading to the destination to a data lake or data warehouse.
The trend is to transform the data after loading the data to the powerful modern data warehouse such as Google BigQuery, Snowflake, AWS Redshift, and Microsoft Synapse. So, ELT rather than ETL is increasingly used to refer the data processing.
I’m adding P to ELT, and it’s “Publishing”. It’s the process of publishing the post-transformation data to exactly where people or another program consume them. We call a “frontline application” in this article.
ELT does not solve the “Data Last-mile Problem”
Let me expand this by a realistic business scenario: Product Qualified Lead scoring (PQL scoring).
Suppose your company is a Software-as-a-Service (SaaS) company. The service is free to sign up to use the basic feature. Your potential customer finds your service through an online ad. Sign up is free but the user must enter their work email and business information.
If you are using online marketing automation tools such as Marketo or Pardot, you can capture the prospective customer’s product discovery channel and their email at this point. But the marketing process typically lacks information on the usage statistics of your service. It’s because such data is typically sitting on the production database.
Or you may have taken one step further to replicate the data from the production database to the data warehouse through an ELT process. You may be a data scientist who came up with a formula or machine learning algorithm to compute a PQL score to indicate which free-tier users would likely convert to paying customers.
But as long as the data is sitting in the warehouse, it’s not going to be utilized. In the case of the PQL score like above, such score should be published to Marketo, Pardot, or Salesforce because that is where the sales and marketing staff do their job. They are too busy to open a business intelligence tool or run queries to find which prospects should be prioritized.
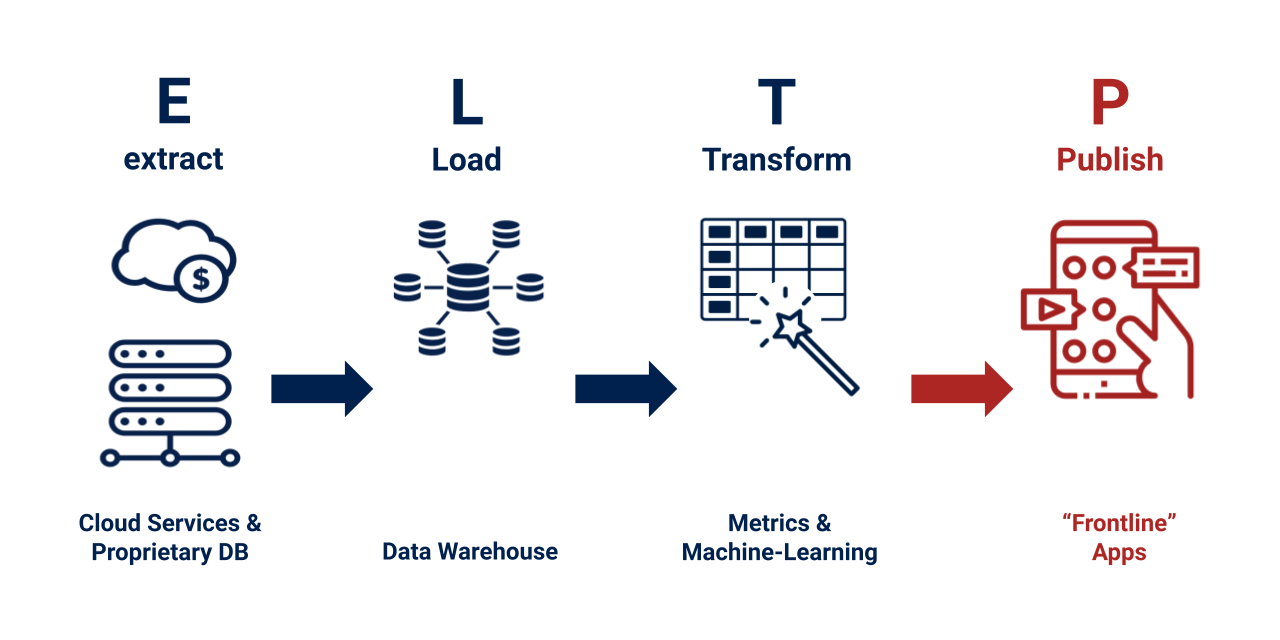
Publish: Push the data out of the warehouse
The importance of publishing the metrics to the frontline applications is critical beyond the product marketing use cases. Another compelling case for SaaS business is customer success. For a subscription-based service, it is crucial to track the health of each subscriber account. Especially for complex business applications, the customer may give up on the product before seeing the value. Are your customers taking the right steps towards the value after signing up, or are they having difficulties starting out?
Enterprise SaaS companies typically have a customer success function to help the new account in the onboarding process and beyond. The product usage statistics and account’s health score would be very helpful only if such information is available right where they do their work such as Zendesk.
ELTP’s P takes care of the last mile problem of information delivery to make the business operation smart, efficient, and lean.
ELTP Automation
Over the years, the ELT business grew and there are so many services to automatically move the data from various online applications to the data warehouse. But there are so few resources and services available to automate data publishing, not to mention no-code solutions.
Lack of a no-code solution does not stop a business from taking advantage of the powerful ELTP process. A little bit of data engineering investment will work as great leverage on the entire business operation.
One of the popular Open Source ELT frameworks is singer.io. Singer.io community builds data extractors called tap and data loader called target. Singer.io’s specification helps the data engineers to mix-and-match tap and target to create the source-destination combo for each business use case. In a typical ELT framework, cloud applications such as Salesforce and Mercato are the data source (tap) and the data warehouses are the destination (target).
When we built P of ELTP, we reversed the designation: For example, we developed a tap program for BigQuery to extract product usage metrics and developed a target program for Pardot. By running this tap-target combination, we automated the process of publishing the product usage data from BigQuery to Pardot so that the marketing and sales team of our clients can fully utilize the PQL metrics with no manual work of moving data around.
Future of ELTP
Data publishing is not limited to human consumption. The computed metrics can be replicated back to the production data store or caching layer to enhance the product’s user experience more optimized and personalized. The metrics could be based on simple statistics or a result of more complex computation by machine-learning. Just by taking care of the last-mile problem and ensure the valuable signal is delivered right where it matters, we can unlock the unseen potential.
In the near future, would expect there will be more new businesses providing no-code solutions and services to close the loop. Until more people realize how powerful it is, we will help businesses with our custom ELTP solution and make more success stories in sales, marketing, and customer success use cases.
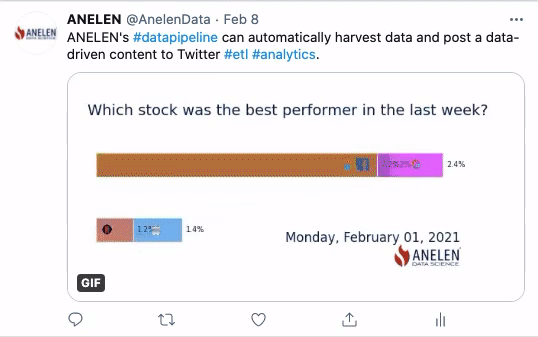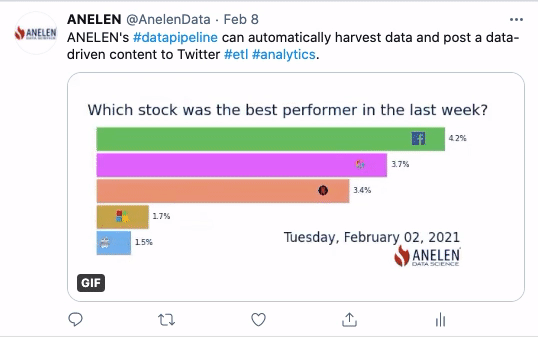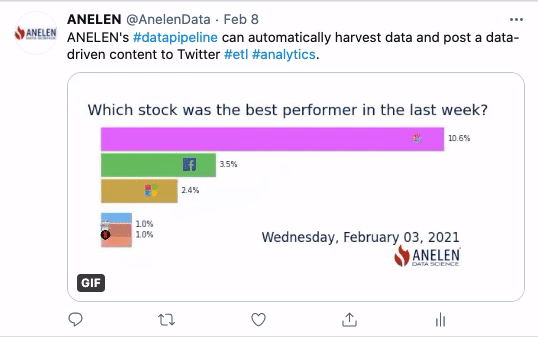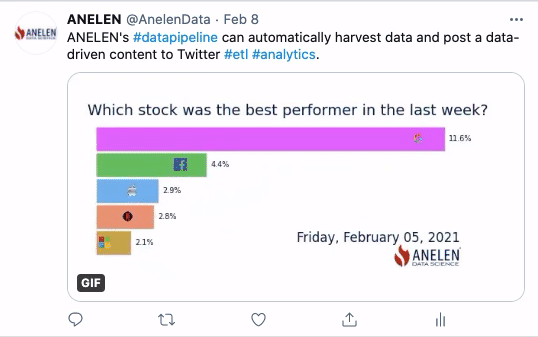
A Fun Demonstration
Here is a fun demonstration of solving the “last-mile problem” of making use of data. These GIF animations are created and posted on Twitter automatically at specified intervals. We extract the data from the sources (geological and financial), transform the data (including the part to produce the animation), and deliver it to where it matters (social media).
About the author
Daigo Tanaka is the CEO and data scientist at ANELEN Co., LLC, a boutique consulting firm focused on data engineering, analytics, and data science. ANELEN’s mission is to help innovative businesses make smarter decisions with data science.