This article presents the business context and a technical deep dive of our serverless approach to data pipeline deployment. handoff: framework for serverless data pipeline orchestration.
Business Context: Helping our customers bring any data anywhere
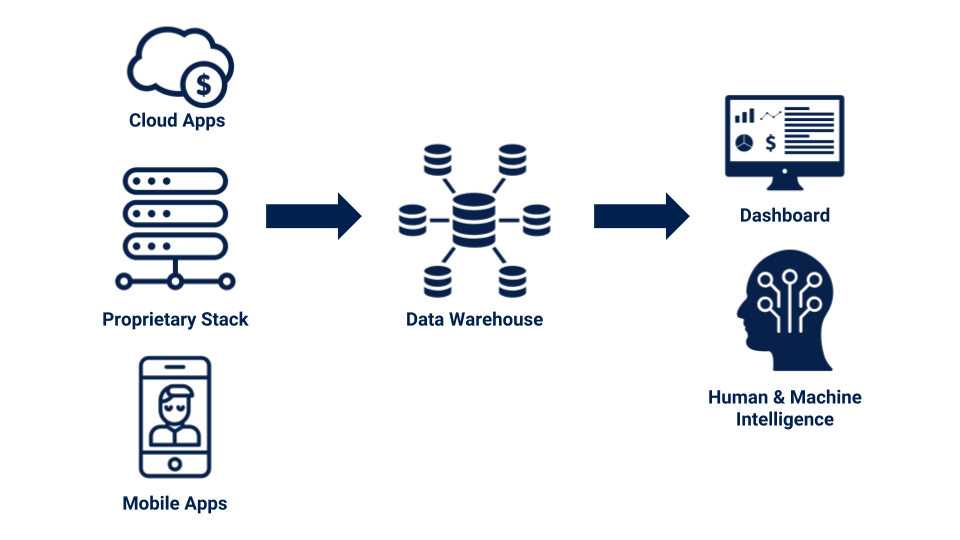
More and more companies have started to leverage cloud applications and their data in order to make their operation lean and effective. For example, D2C (direct to consumer) companies produce niche household products and ship directly to their customers instead of relying on a traditional retail distribution channel. In doing so, a D2C company may use a marketing automation platform like Marketo or Pardot, run ads on Facebook and Google, and manage the supply chain with Flexport: All of these applications produce customer experience data. It is a common practice to extract data from cloud services and load them into a data warehouse (DWH). By combining data sources and analyzing them together, the business continuously improves the quality of the customer experience.
We are a technology-leveraged service company offering custom ETL/ELT solutions. ETL stands for Extracting, Transforming, and Loading of data. ELT workflows are becoming popular. Data are extracted and loaded into the data warehouse before transformation is executed by a massively parallel modern DWH engine.
The demand for implementing data pipelines is growing at an unprecedented pace. Data replication services such as Fivetran and StitchData provide data connectors for popular cloud applications such as Salesforce and Zendesk. However, those companies cannot support the long-tail of cloud applications in the Software as a Service (SaaS) market. If a cloud application is not supported, a business need a custom data engineering job, but not every company can afford to developing an internal data engineering team.
That is why fully-managed ETL services like ours are becoming the new option: With a fraction of the cost of hiring a data engineer, businesses can install the tailor-made data pipeline service.
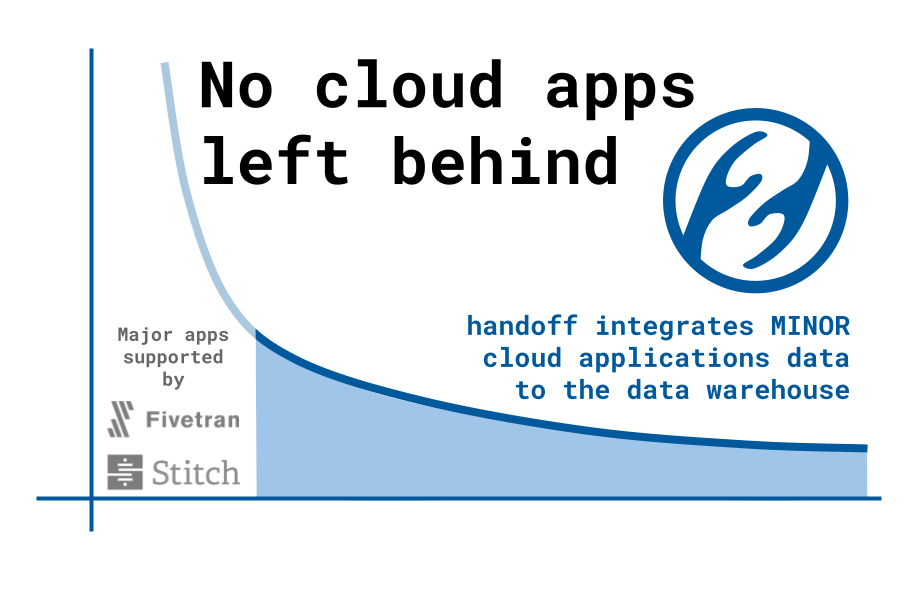
Bring any data anywhere. Try risk free >> handoff.cloud
In the rest of the article, we will share the technical solution that made our service possible.
Technical challenges and solution
If you are the director of data engineering for your company’s internal operations, it makes sense to set up an Apache Airflow or subscribe to a managed service by Astronomer or Google Cloud Platform. Instead, we are a lean team helping others to perform the data integration of cloud applications in the long tail. Simultaneously serving the data pipelines for many different clients change the technical requirements a lot. The most important part is to provide separate CPU, memory, and storage capacities for each client. We wanted to achieve this with maximum flexibility. When we started we only had a few data pipelines to manage, but we expected the number to rapidly grow.
AWS Lambda vs. Fargate
We went for a serverless approach. Our first prototype used Amazon Web Services (AWS) Lambda. It was quick to implement. The pay-as-you-go pricing was very attractive. We didn’t have to pay for idling the virtual machine or deal with peak-time auto-scaling challenges. But we soon realized that Lambda’s 15 minutes processing time limit is not enough for some tasks. So we switched to Fargate, another pay-as-you-go serverless platform by AWS. It has no time limit and the life-cycle management and scaling of computing resource is fully managed by the platform.
Compared to Lambda, Fargate’s deployment process is much more complex. Lambda could be deployed just by writing a script file. Fargate deployment involves Docker image creation, pushing the image to Elastic Container Registry, creating resources such as Virtual Private Cloud and Security Groups, defining the Fargate task, managing the Policy, and so on.
Birth of handoff: A serverless data pipeline orchestration framework
The painful Fargate deployment process gave us the idea to implement a command-line interface (CLI) that we later named “handoff”. handoff simplifies the deployment steps for AWS Fargate. We may also provide a multi-cloud capability in the future: handoff unifies the commands to deploy to AWS, Microsoft Azure, Google Cloud Platform, and so on.
handoff describes the data pipeline logic in a YAML file. The first thing is to describe the installation of the modules required by the pipeline logic:
project.yml:
version: 0.3 |
As you can see, handoff is created primarily for Python. You can install modules in separate virtual environments if needed: handoff automatically generates multiple virtual environments. In local testing, you can install modules by running:
handoff workspace install --project <project_dir> --workspace <workspace_dir> |
The pipeline logic is described as groups of tasks. In a task group, each command can be linked as a Unix pipeline:
tasks: |
The pipeline is particularly useful in deploying memory-efficient tasks such as the ELT task by singer.io framework.
The following command runs the task locally:
handoff run local -p <project_dir> -w <workspace_dir> |
Doing more than a simple data replication task
handoff also implements simple control flows such as for-each and fork. You can also define a task beyond simple ETL. Look how we automate the task of fetching stock market data, make a GIF animation, and post it on Twitter:
A fun demo: handoff's #datapipeline can automatically harvest data and post data-driven content to Twitter #etl #analytics. pic.twitter.com/0ITR771mh9
— handoff (@handoffcloud) April 1, 2021
Deployment features
We estimate authoring pipeline logic is just 20% of the ETL development. To run the pipeline in production, we need to implement management of:
- Run-time configuration
- Secret keys
- Scheduling
- Logging
- Monitoring
- Containerization
…and the list goes on. handoff’s project.yml helps to keep those organized and it is intuitive to understand. Here is an example of project.yml:
vars: |
The commands to execute the containerization and the deployment are also simple and intuitive:
# Push project configuration, supporting files, and secrets to AWS |
handoff simplifies development and deployment. Without handoff, you would have to author CloudFormation templates, deal with boto3 commands to transfer files to S3, figure out a way to encrypt and store the secrets, configure the CloudWatch for logging and metrics, etc.
For a full handoff tutorial, please visit https://dev.handoff.cloud
We made handoff a public project on GitHub so every engineer having a similar challenge can use it. We also welcome collaborators to improve this new framework.

What’s next?
As we mentioned earlier, we may support deployment to other cloud platforms such as Microsoft Azure and Google Cloud Platform. Unifying the deployment commands for multi-cloud would be very useful in quickly switching platforms.
We also prototyped a web UI built on top of the CLI:
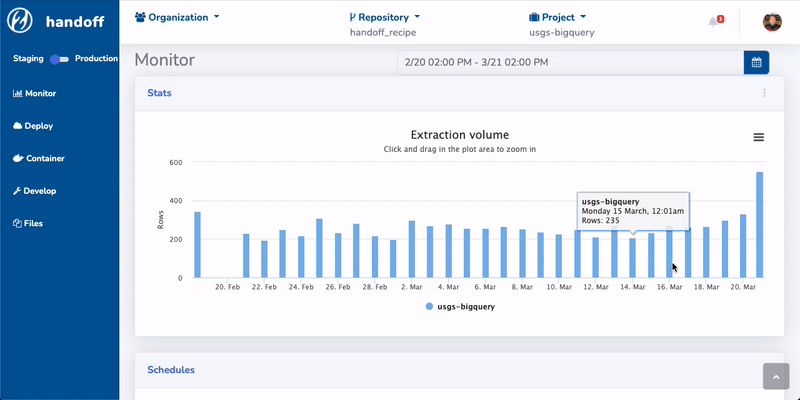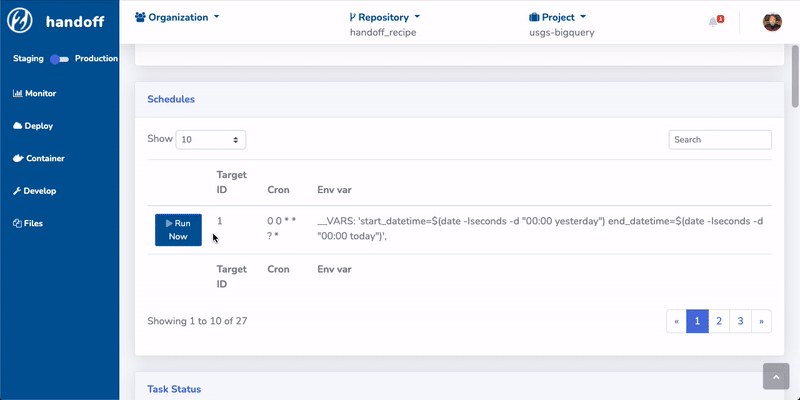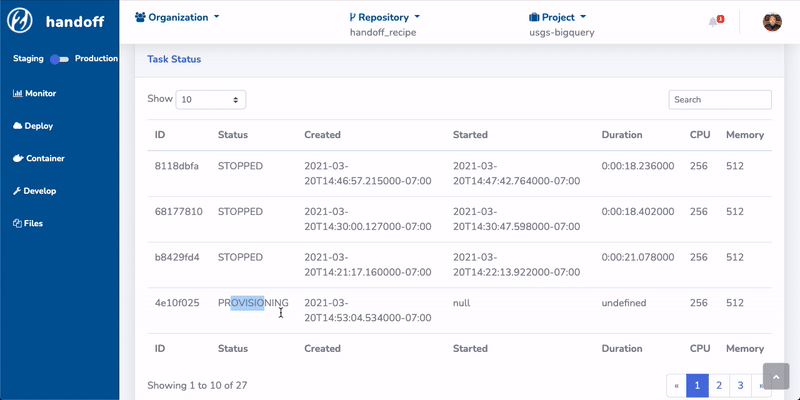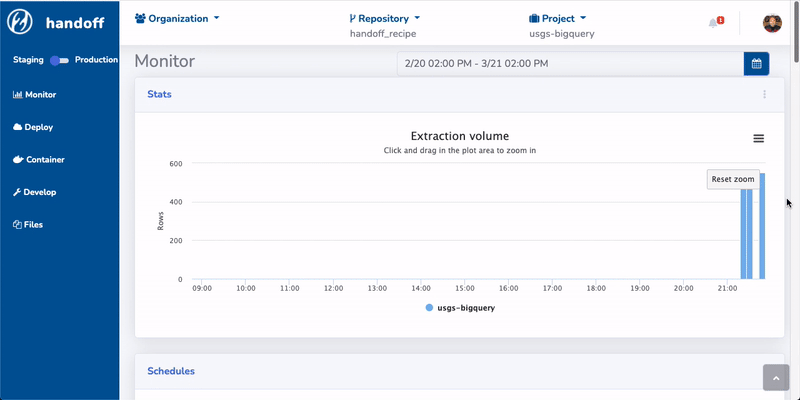
The web UI could be running as a stand-alone application on your local machine. It will spin up a local web server. You can interact with handoff via the web UI and the backend connects to cloud resources. It can also be hosted on a server for enterprise use cases.
Conclusion
AWS Fargate lets us create a cost-effective and scalable solution for ETL deployment. However, it hasn’t been a popular approach due to the complex deployment process. handoff, a serverless data pipeline orchestration framework simplifies it. handoff also manages the various aspects of the orchestration such as security and monitoring. We made handoff an open-source project so that the data engineering community can benefit from it and collaborate for futher innovation.