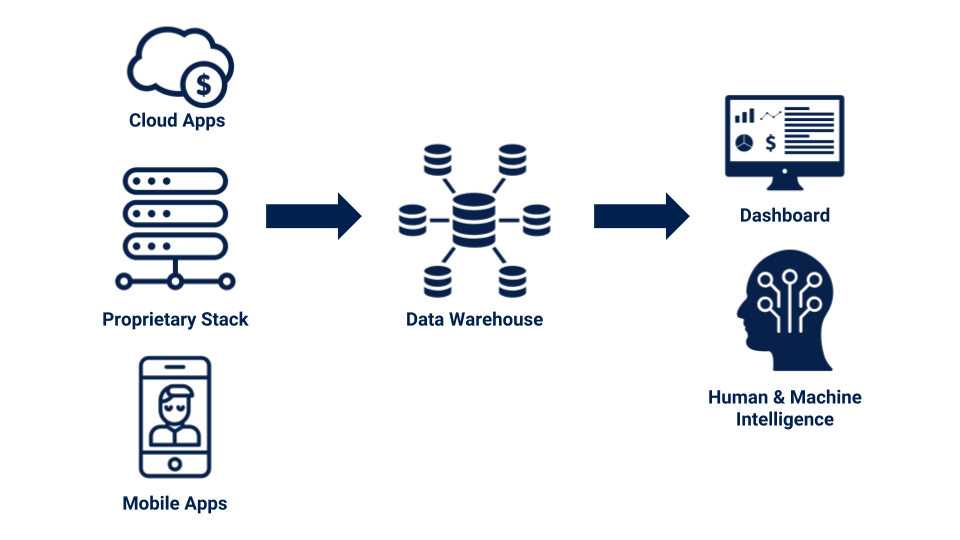
Extracting and organizing the data is the first step before any analysis can begin. Ironically, this first step is the most challenging part of analytics in many organizations.
Anelen introduced kinoko.io earlier this year. It’s a tailor-made ETL process for each client so we can collect the data from non-major and proprietary cloud applications. Such data sources are not typically supported by boilerplate ETL services. ETL services including kinoko.io access the data from the Application Programming Interface (API). However, in many circumstances, the data we need may exist somewhere not accessed through API.
The price information on U-Haul, a truck rental company, is a good example of the data only available through web pages:
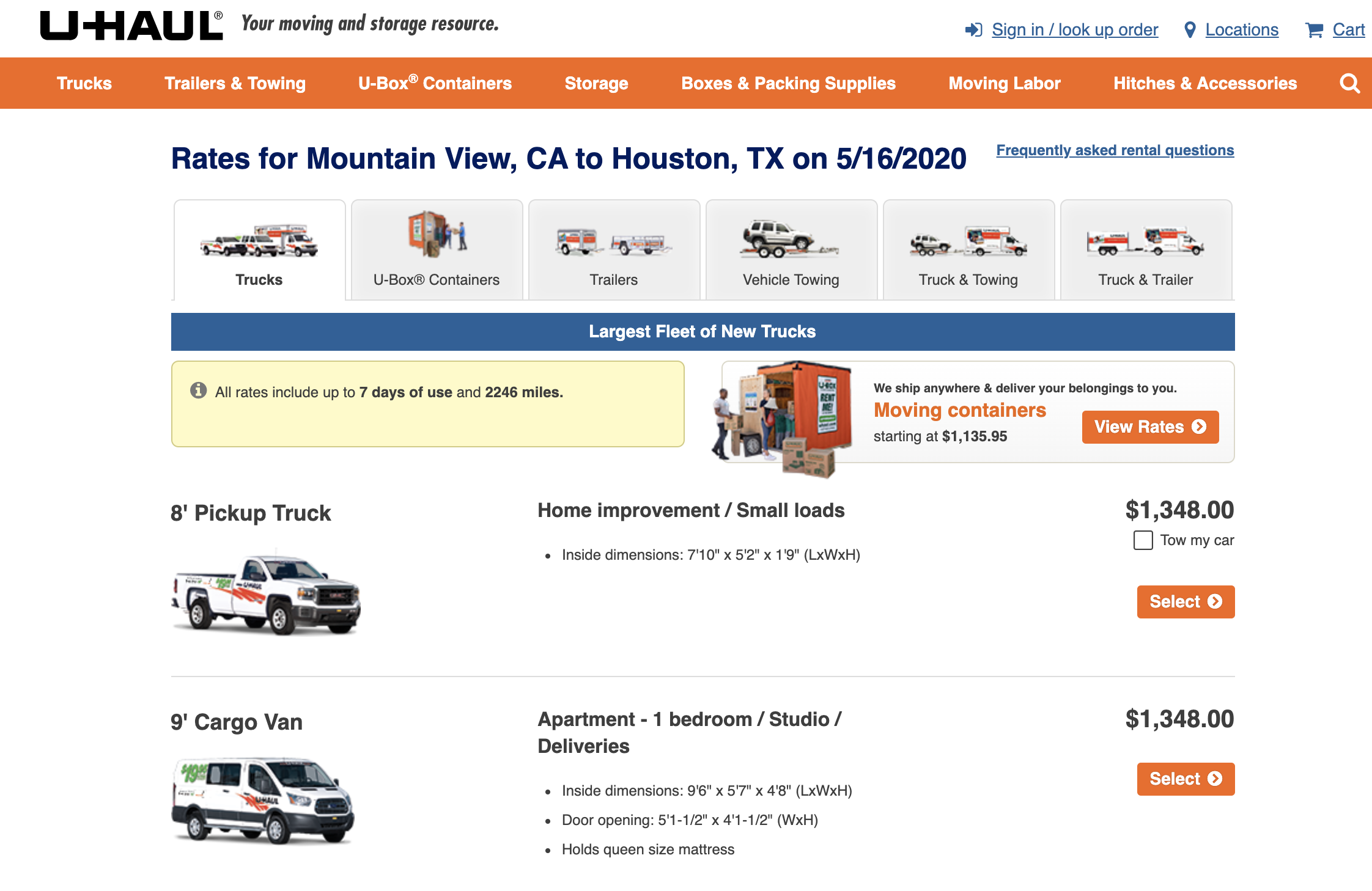
Recent news reported the tech companies started to move their workforce to other areas. Even before that, people have been leaving the San Francisco Bay Area due to the high cost of living. The coronavirus pandemic seems to have only reinforced this trend. As a result, one-way truck rental prices from the Bay Area to outside destinations have been much higher than the opposite directions. Jabus Tyerman came up with an index called “U-Haul Moving Index” (UMI) to show the asymmetricity of the rental truck prices:
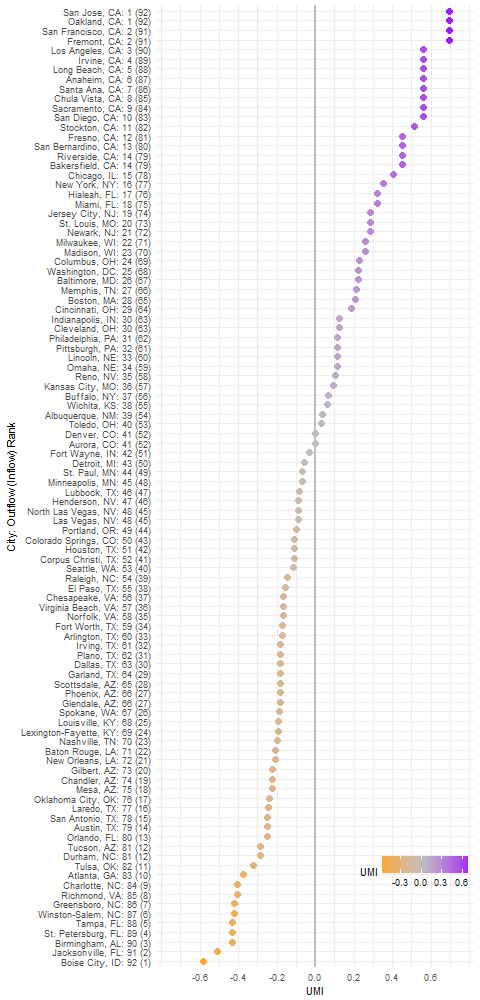
(The figure adopted from U-Haul pricing and where people are moving)
As you can see at the top of the figure above, the cities in the Silicon Valley such as San Jose, Oakland, San Francisco, and Fremont are the most expensive pickup location of the rental truck.
According to his article, Tyerman collected the prices from the pickup-dropoff combinations of the top 100 populated US cities. That is 10,000 price entries. I don’t know how he collected the data from U-Haul. But if he collected from the U-Haul web site, he would need to either manually navigate the web site, or create a program to automatically crawl the pages to extract the data.
Web crawler + ETL pipeline on kinoko.io
I added the web crawling capability to kinoko.io so we can collect the data like U-Haul price information from the web, clean, organize, and store on the data warehouse like Google BigQuery and AWS Redshift.
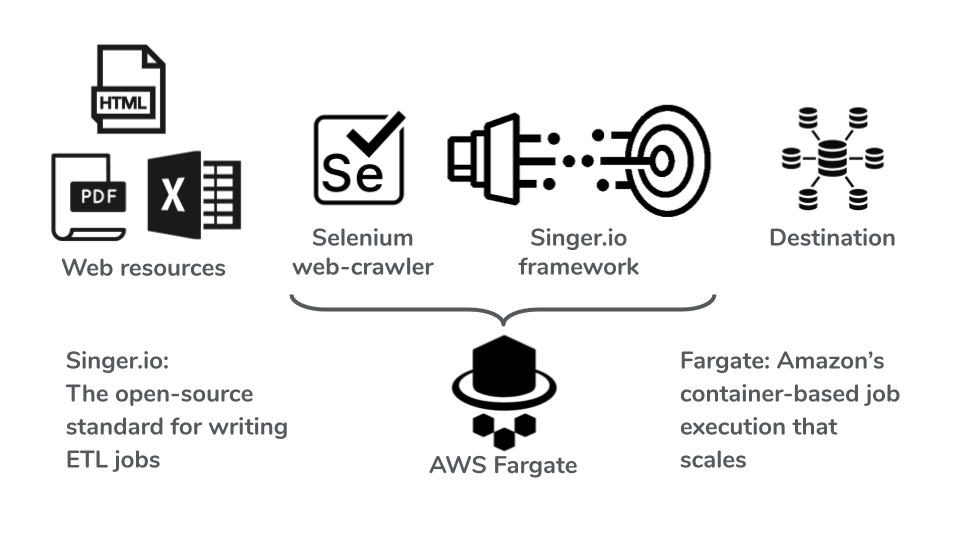
In this framework, the data is extracted, loaded, and transformed in the following manner:
- Step 1: A human identifies the steps to retrieve the information from a single page. While she or he operates the web browser, Selenium IDE monitors the keystrokes and mouse clicks and records as a script written in a computer language such as Python. (*)
- Step 2: The Selenium script runs by varying the inputs such as the pickup city and date for the truck rental.
- Step 3: Extract the target data (e.g. price) from the downloaded web resources such as HTML, PDF, and Excel files. A parsing logic must be constructed for the file format and content. Organize the data in a table format.
- Step 4: Using singer.io framework, pass each data record from the singer-tap to the singer-target programs. The singer-target code writes the record to the destination data warehouse.
Instead of running Step 2 to 4 for one page at a time, we can deploy many processes all at once using AWS Fargate to dramatically shorten the required time.
*) Many web sites including U-Haul incorporate CAPTCHA and it makes web crawlers more difficult to access the pages. kinoko.io’s crawler automatically connects to thousands of human crowd workers all over the world to pass the CAPTCHA process in a very short amount of time.
Case study: Education statistics data on NCES
As a demonstration, kinoko.io web-crawler was applied to collect the education statistics data on the National Center for Education Statistics. The target data, called Common Core of Data, is a list of over 100,000 public schools. The data contains information such as addresses and phone numbers of each school as well as useful statistics such as the number of students and teachers. The education researchers use the data as a reference for various research.
The data can be downloaded as Excel files, only after many clicks of page navigation for each state. The download links cannot be guessed because the Excel file is generated dynamically after the user submits the web form.
To save the research assistants from the finger sprains, kinoko.io web-crawler was configured to simulate the human access on the web page. Then the 50 instances of the crawler were deployed on AWS Fargate. The data extraction finished in a matter of 30 minutes (**), compared to hours of time required for a human research assistant. The crawler program was combined with the kinoko.io ETL process to load the content of each Excel file into the data warehouse (BigQuery).
(**) This could have been a few minutes instead of 30 minutes if I deployed all the instances simultaneously. I roll out the deployment in an interval so I eliminate the chance of taking down the NCES site.
After the data quality control, I made this dataset public so the education researchers benefit from this effort. The figure below shows a heatmap of USA counties based on the average student-teacher ratio together with the distribution of the ratio and the counties with the highest student-teacher ratio, potentially indicating negative eduction quality:
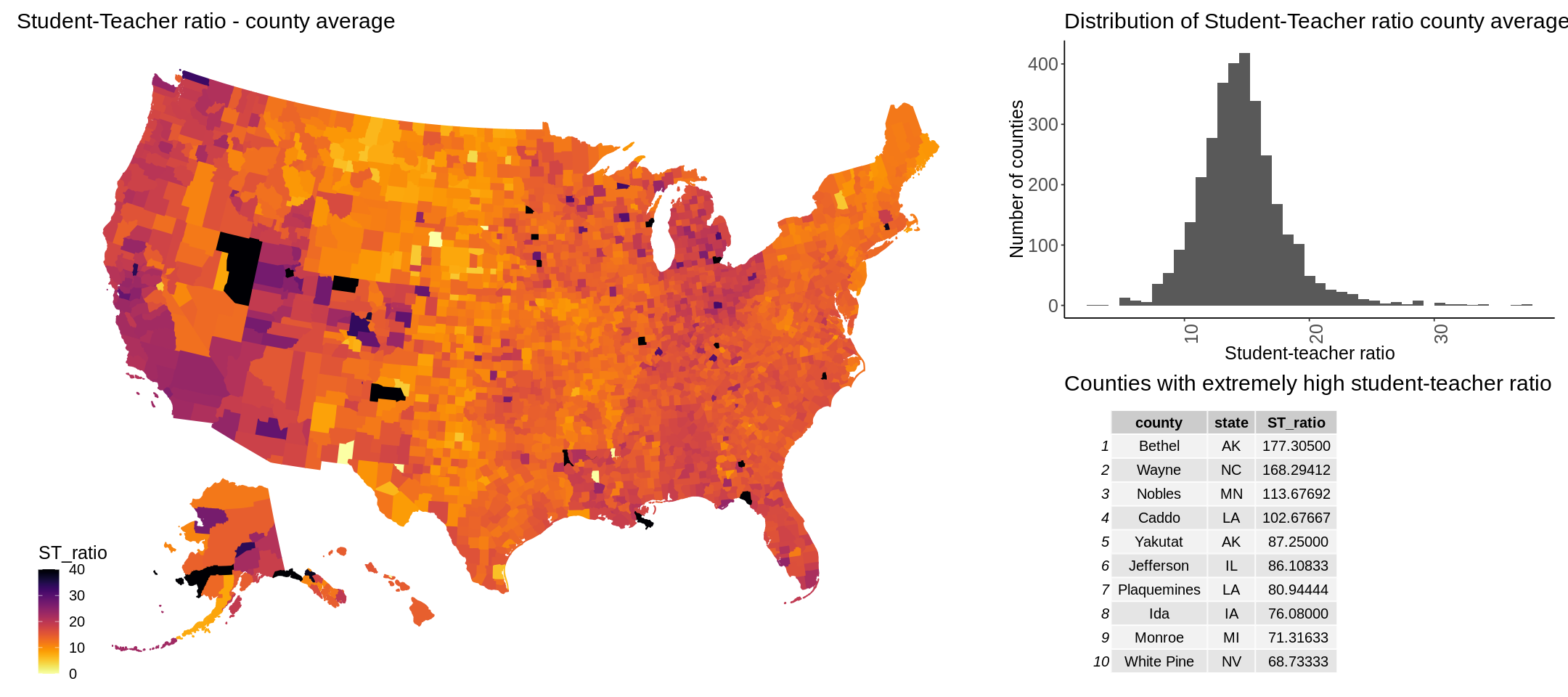
This example, together with the source code to access the data on BigQuery is presented on a public Google Colab notebook
Conclusion
While most ETL service only supports major cloud applications as a data source, Anelen’s kinoko.io not only accesses any API endpoints but also is capable of collecting data from any web resources (HTML, PDF, Excel, etc) with the web crawling technology. The collected data then organized and stored in the data warehouse. Once the data is in the high-performance data warehouse, we can run complex data analysis combining with the data from other sources and/or create machine-learning applications.
Find out more!
I hope this introduction was informative and relatable to your business. If you would like to find out more what Anelen can do for your data challenge, please simply contact hello@anelen.co (.co, not .com don’t get your email lost elsewhere!) or schedule a free discovery meeting with the scheduler.