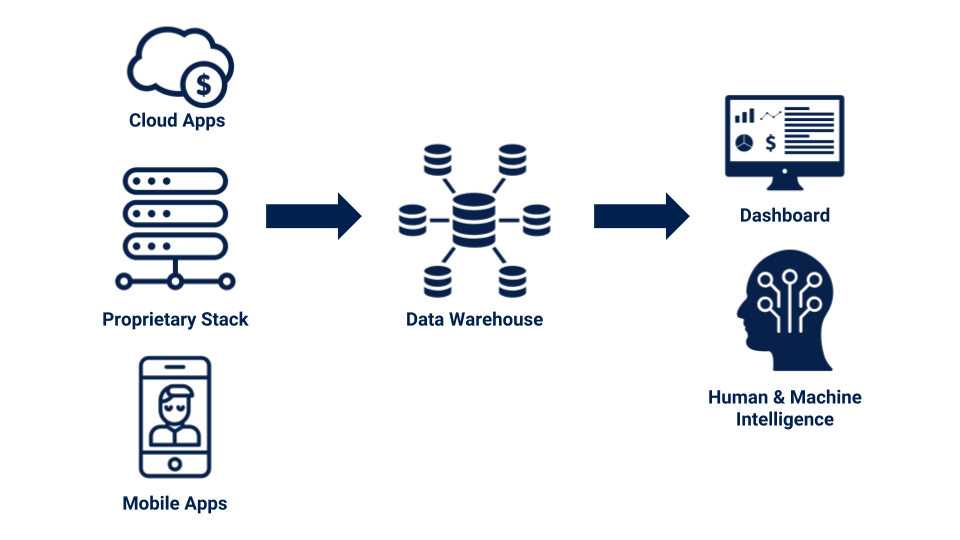
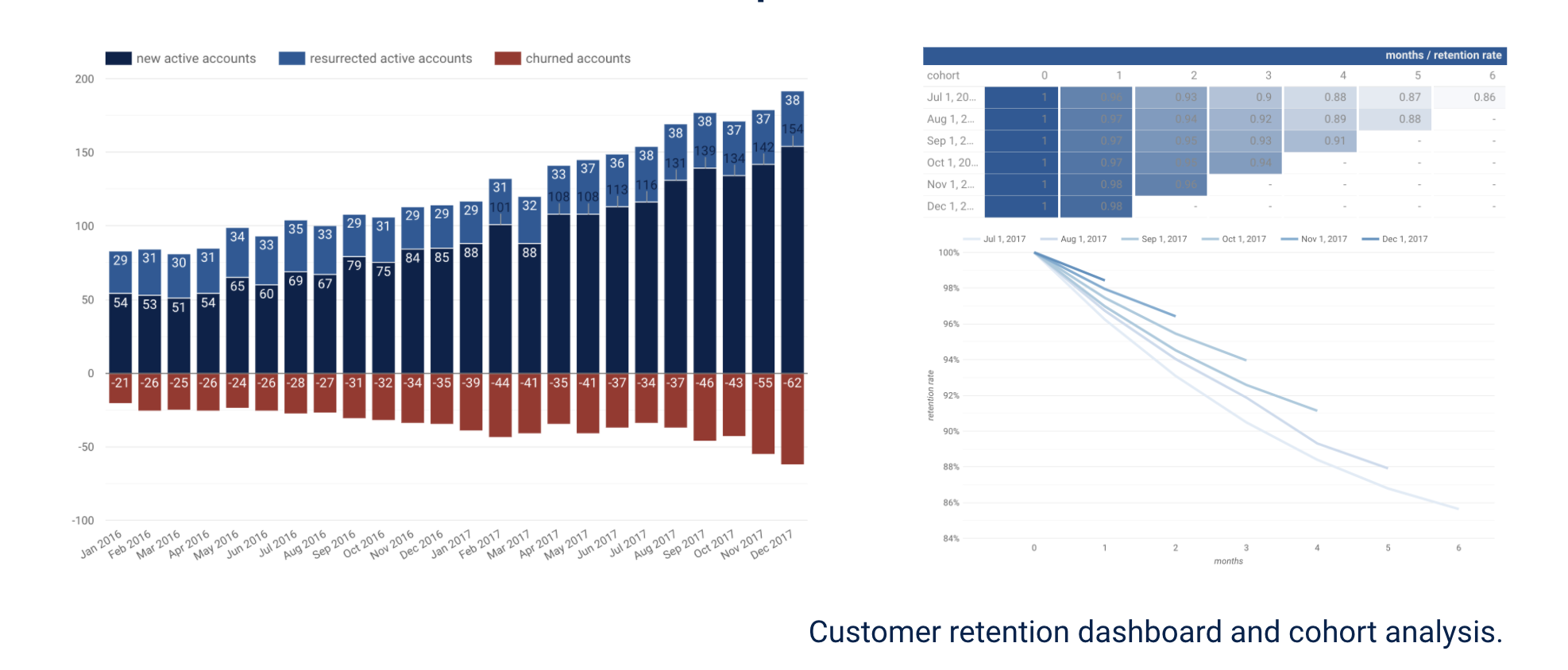
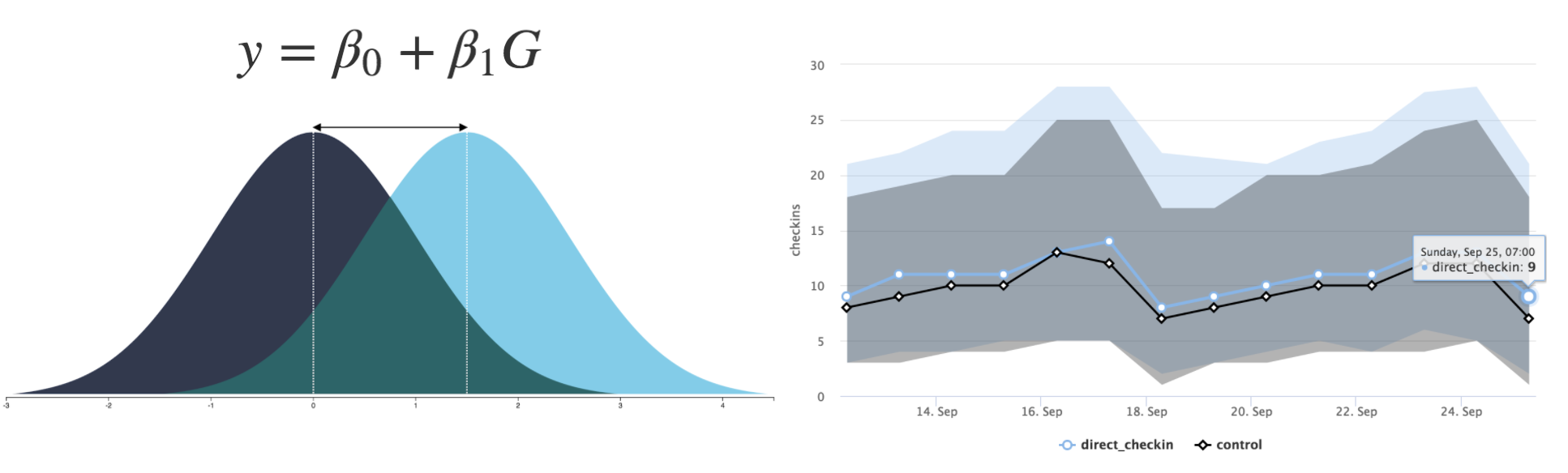
In this article, I am going to introduce Data Sprint™. It is a framework that makes data science and analytics team deliver maximum business value.
Problem: Data request overload
Anelen’s mission is to help innovative businesses make smarter decisions with data science. We have been helping fast-paced startups to make data-driven product decisions. Typically, the product team we serve are mature enough to recognize that they need to make evidence-based decisions using the product engagement data they have been accumulating. They may have an internal data scientist and analyst (I call them collectively “analysts” in this post) to conduct the analysis or they outsource such tasks to a highly-skilled company like us for a cost-effective solution. Whatever the execution model is, I have been seeing a common problem for many years that block data the analysts from delivering a maximum value:
Analysts are pulled into ever-increasing simple data compilation while they are also committed to deeper insight generation and machine-learning model building.
When the product managers and other team members realize the value of data-driven decision-making, the next thing happens is an abuse or lack of a sense of return-on-investment (ROI). If you an analyst, you know how much it costs to provide an answer to a seemingly simple question such as “counting the number of active users”. (What do you mean by active? What period? Do you need to compile a cumulative sum of each month? How do you use the data anyways?…) Yet, non-analyst members throw those “simple” questions like an innocent child asking for more and more…assuming it is easy to compute the numbers just because their questions are so simple.
Soon, the analysis’s to-do list blows up. At the end of the quarter, she realizes that she does not have enough time to complete a thorough analysis of a high-value project, committed at the beginning of the quarter. She spent 80% of the time writing simple SQL just because the product manager casually walks at her desk in the open plan office every day to ask to compute yet another product metrics.
Solution: Data Sprint™
The analyst needs to learn to say no. Better yet, any data requests should first get an estimation and prioritized based on the ROI. It takes tremendous focus in order to conduct a robust analysis, so the analyst should be shielded from ad-hoc requests. At the same time, the analyst should sprint towards the target deadline once committed to an analytic task. An intermediate work should be reviewed by the stakeholders periodically to see if the insight generated so far is good enough, the scope should be redefined, or the project should be deprioritized over others.
If you see the artifacts of the data analysis as a product, the problem sounds more and more similar to the motivation addressed by Scrum, the agile software development framework. Borrowing the idea from Scrum, here is how Data Sprint (TM) would look like:

- Every analytics request and data science project should be first recorded in a Data Backlog (analogous to product backlog in Scrum).
- The analytics effort should be time-boxed just as software team does as Sprint (Let’s call it Data Sprint).
- At the beginning of each Data Sprint™, the backlogs are ordered based on the priority by the owner of the analytics resource (Product Owner in Scrum).
- The size of each task is estimated up-front. The estimation or target date for the delivery is communicated to the requesters. (The requester may cancel the request after seeing how much time is required before their business question is answered.)
- Once the Sprint starts, no ad-hoc requests should be in the way of the committed requests. The new request is queued up in the Data Backlog to be prioritized at each Sprint.
- At the end of the Sprint, the results are compiled and presented for the review.
Special considerations for analytics (vs. software development)
Some organizations have data analysts for each product unit. Some organizations choose to have a centralized analytics and data science team or can afford only one or a few analysts to take requests from the entire company. The execution models would look a little different between the two organizations models, but the core idea behind the maximizing the value based on the time-boxed strategy would be the same.
At Anelen, we take the data request at any time from the client organization, only through a designated request form. The committed tasks for the Sprint and the current prioritization are always visible to all the people with a request privilege. This encourages the negotiation among the requesters rather than to the analyst when they see a conflict of prioritization in the Data Backlog. We ask for a deadline for such negotiation so we have a clear list of committed tasks as a new Sprint begins.
Some tasks are long-term research projects, but each Sprint should produce some types of artifacts that show the deepened understanding of the problem or generated insights before a product such as a machine learning model is finally produced after many months. Such intermediate results should be also treated as a product to be reviewed, and the analyst should make all the effort to present them in a comprehensive manner to business audiences.
A Data Sprint™ can be woven into a Product Sprint. The product manager makes hypotheses as they make product decisions. Such hypotheses can be confirmed or rejected before or after the feature releases by incorporating so-called Data Review, where analysts show the evidence and recommendations based on the analytics work, at each Sprint and quarterly reviews:

Conclusions
The productivity of analytics and data science is determined by the value of information the team extracted from the data. It is always important to compute accurately, and it is often crucial to understand the required speed and thoroughness of the analysis. The time-boxed approach addressed by Data Sprint™ framework helps to continuously deliver the result that actually matters to the decision makers.
Daigo Tanaka, Ph.D. is the founder of Anelen Co., LLC, whose mission is to help innovative businesses make smarter decisions with data science. He introduced an agile start-up methodology to a pre-Stage A startup and helped to raise the total of $105MM. If you need a consultation on the topic of a startup operation and data science, please contact hello@anelen.co (.co, not .com don’t get your email lost elsewhere!) or schedule a free discovery meeting with the scheduler.